
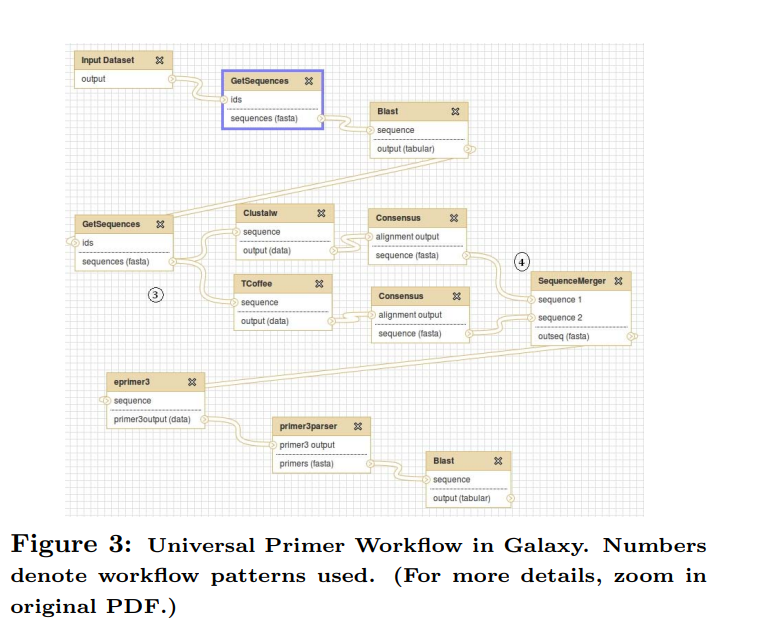
Meta-workflows: Pattern-based interoperability between Galaxy and Taverna
Taverna and Galaxy are two workflow systems developed specifically for bioinformatics applications. For sequence analysis applications, some tasks can be implemented easily on one system but would be difficult, or infeasible, to be implemented on the other. One solution to overcome this situation is to combine both tools in a unified framework that seamlessly makes use of the best features of each tool. In this paper, we present the architecture and implementation of a high-level system that provides such a solution. Our approach is based on meta-workflows and workflow patterns. We present a
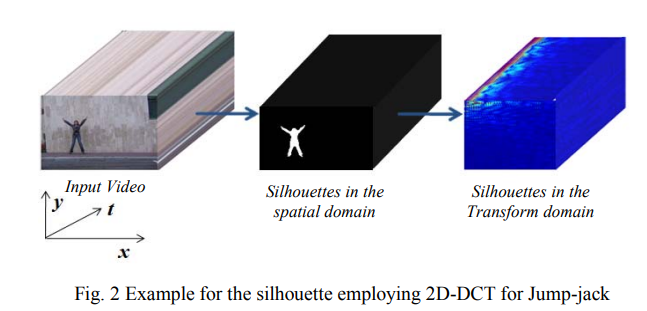
Human action recognition employing TD2DPCA and VQ
A novel algorithm for human action recognition in the transform domain is presented. This approach is based on Two- Dimensional Principal Component Analysis (2DPCA) and Vector Quantization (VQ). This technique reduces the computational complexity and the storage requirement by at least a factor of 45.27, and 12 respectively, while achieving the highest recognition accuracy, compared with the most recently published approaches. Experimental results applied on the Weizmann dataset confirm the excellent properties of the proposed algorithm, which lends itself to real-time economic implementation

Human action recognition employing 2DPCA and VQ in the spatio-temporal domain
In this paper a novel algorithm for human action recognition is presented. This approach is based on Two-Dimensional Principal Component Analysis (2DPCA) and Vector Quantization (VQ) in the spatial-temporal domain. This method reduces computational complexity by a factor of 98, while maintaining the storage requirement and the recognition accuracy, compared with some of the most recent approaches in the field. Experimental results applied on the Weizmann dataset confirm the excellent properties of the proposed algorithm. © 2010 IEEE.
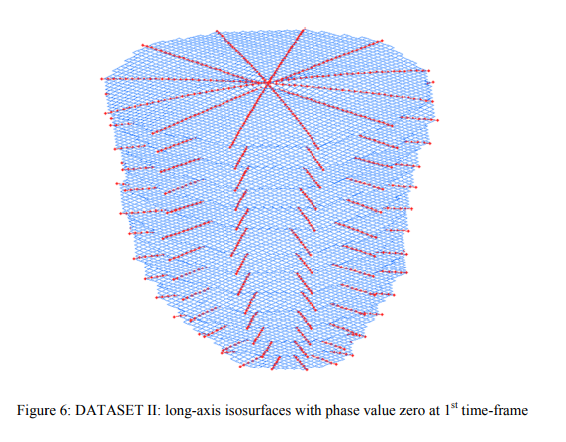
3D motion tracking of the heart using Harmonic Phase (HARP) isosurfaces
Tags are non-invasive features induced in the heart muscle that enable the tracking of heart motion. Each tag line, in fact, corresponds to a 3D tag surface that deforms with the heart muscle during the cardiac cycle. Tracking of tag surfaces deformation is useful for the analysis of left ventricular motion. Cardiac material markers (Kerwin et al, MIA, 1997) can be obtained from the intersections of orthogonal surfaces which can be reconstructed from short- and long-axis tagged images. The proposed method uses Harmonic Phase (HARP) method for tracking tag lines corresponding to a specific
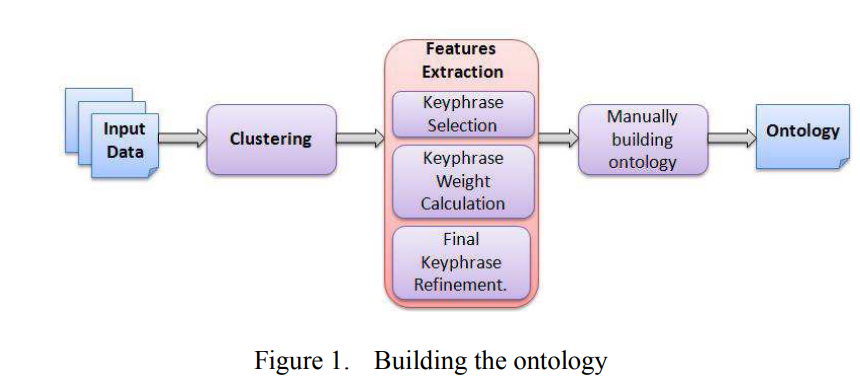
TopicAnalyzer: A system for unsupervised multi-label Arabic topic categorization
The wide spread use of social media tools and forums has led to the production of textual data at unprecedented rates. Without summarization, classification or other form of analysis, the sheer volume of this data will often render it useless and human analysis on this scale is next to impossible. The work presented in this paper focuses on investigating an approach for classifying large volumes of data when no training data and no classification scheme are available. Motivation for this work lies in encountering a real life problem which is further described in the paper. The presented system
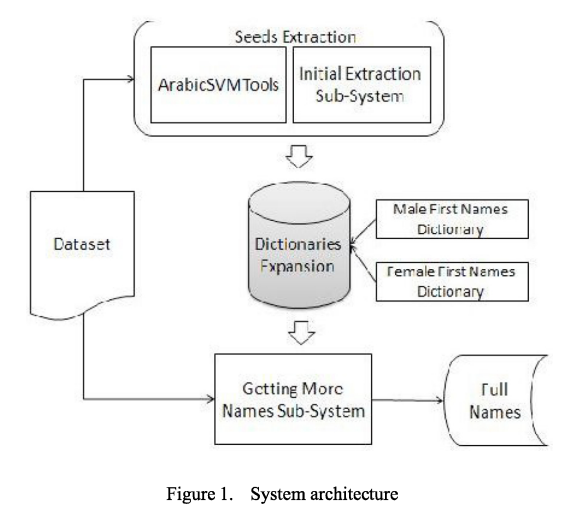
Person name extraction from modern standard Arabic or colloquial text
Person Name extraction from Arabic text is a challenging task. While most existing Arabic texts are written in Modern Standard Arabic Text (MSA) the volume of Arabic Colloquial text is increasing progressively with the wide spread use of social media examples of which are Facebook, Google Moderator and Twitter. Previous work addressed extracting persons' names from MSA text only and especially from news articles. Previous work also relied on a lot of resources such as gazetteers for places, organizations, verbs, and person names. In this paper we introduce a system for extracting persons'
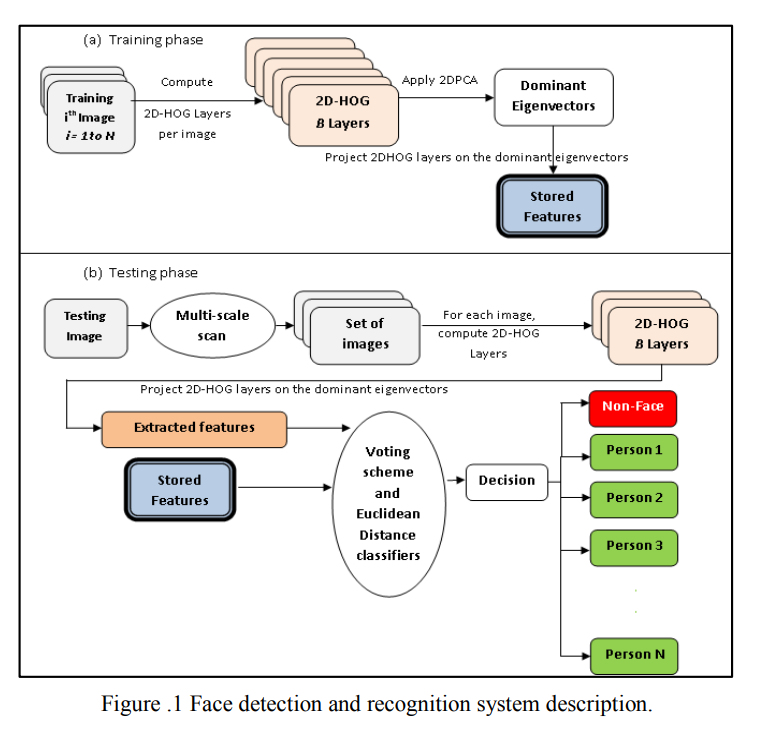
A novel algorithm for simultaneous face detection and recognition
Face detection and recognition has been introduced in many real world applications. Several algorithms have been implemented for either detection or recognition. In this paper, a novel algorithm, which simultaneously detects and recognizes facial images employing the same method, is presented. The proposed algorithm is based on a new 2D representation for the Histogram of Oriented Gradients (2D-HOG) in conjunction with 2DPCA for feature extraction. Experimental results conducted on existing datasets, FERET, ORL, UMIST, JAFFE, and MIT-CMU, achieved better accuracy and running time compared with
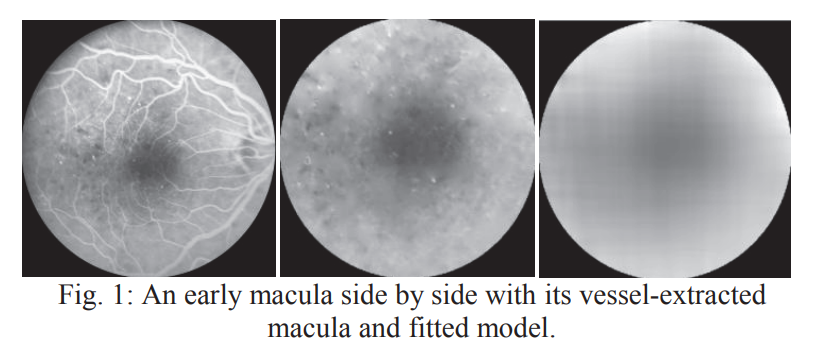
Quantitative assessment of Diabetic Macular Edema using fluorescein leakage maps
Diagnosis of Diabetic Macular Edema (DME) from Fundus Fluorescein Angiography (FFA) image sequences is a standard clinical practice. Nevertheless, current methods depend on subjective evaluation of the amount of fluorescein leakage in the images which lack reproducibility and require well-trained grader. In this work, we present a method for processing FFA images to generate a fluorescein leakage map that can be used for quantitative evaluation of DME. An essential step in the proposed method is to model the spatial distribution of the image intensity within the macula. This model, which
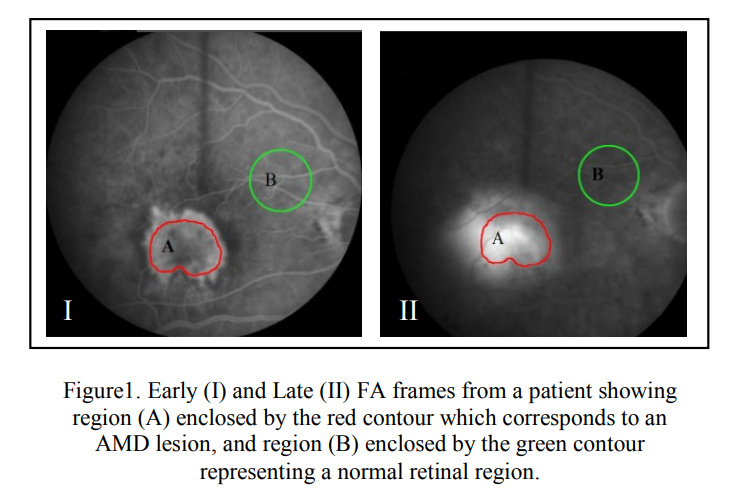
Quantitative assessment of age-related macular degeneration using parametric modeling of the leakage transfer function: Preliminary results
Age-related macular degeneration (AMD) is a major cause of blindness and visual impairment in older adults. The wet form of the disease is characterized by abnormal blood vessels forming a choroidal neovascular membrane (CNV), that result in destruction of normal architecture of the retina. Current evaluation and follow up of wet AMD include subjective evaluation of Fluorescein Angiograms (FA) to determine the activity of the lesion and monitor the progression or regression of the disease. However, this subjective evaluation prevents accurate monitoring of the disease progression or regression
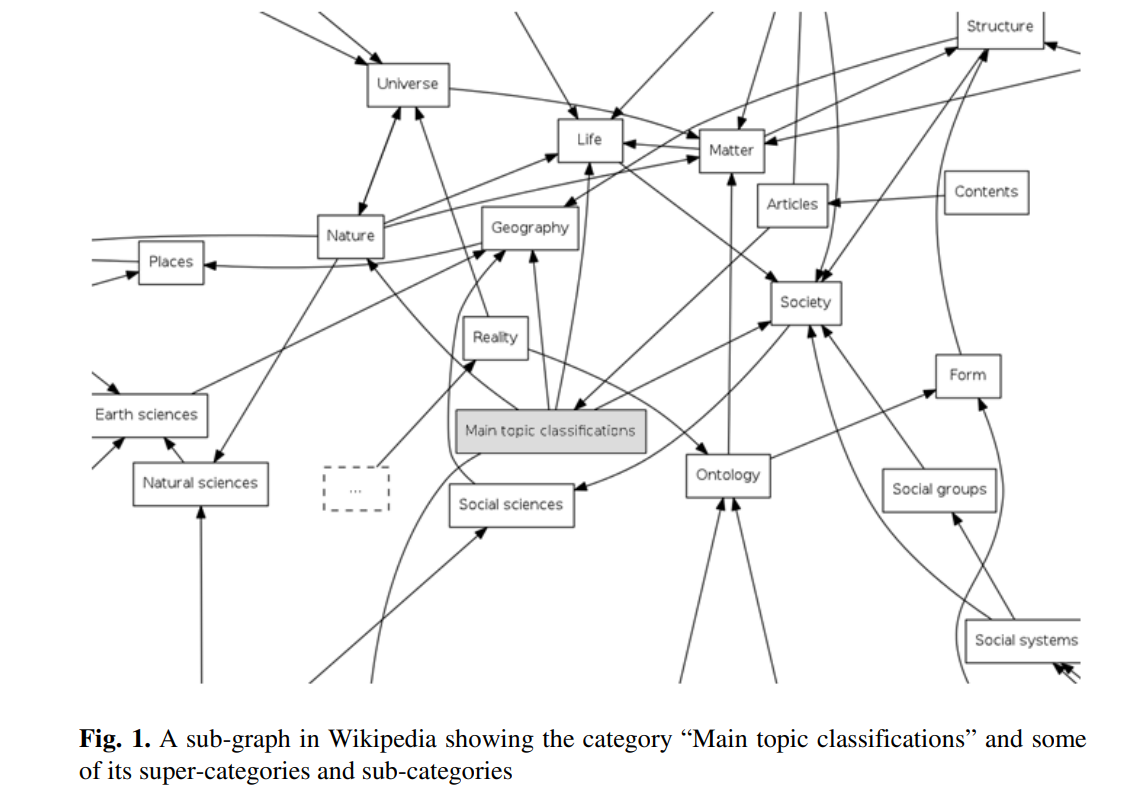
An approach for deriving semantically related category hierarchies from Wikipedia category graphs
Wikipedia is the largest online encyclopedia known to date. Its rich content and semi-structured nature has made it into a very valuable research tool used for classification, information extraction, and semantic annotation, among others. Many applications can benefit from the presence of a topic hierarchy in Wikipedia. However, what Wikipedia currently offers is a category graph built through hierarchical category links the semantics of which are un-defined. Because of this lack of semantics, a sub-category in Wikipedia does not necessarily comply with the concept of a sub-category in a