
Towards mature temporal accuracy assessment of processors models and simulators for real-time systems development
Modeling and simulation are becoming extensively used in embedded and Real-Time Systems (RTSs) development throughout the development life-cycle, from the system-level design space exploration to the fine grained time analysis and evaluation of the system and even its components performance. At the core of these systems lies the processor which has been also the center of attention for most of the modeling and simulation efforts related to RTS simulation. Although the temporal accuracy of such models and simulators is of critical importance for Real-Time (RT) applications, it is not yet mature

Community assessment to advance computational prediction of cancer drug combinations in a pharmacogenomic screen
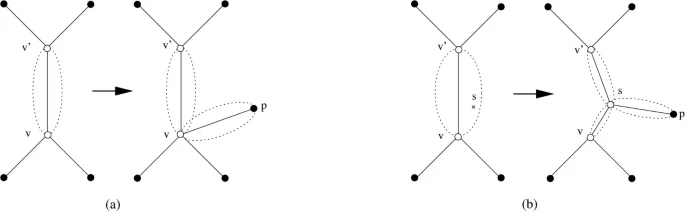
A fast algorithm for the multiple genome rearrangement problem with weighted reversals and transpositions
Background: Due to recent progress in genome sequencing, more and more data for phylogenetic reconstruction based on rearrangement distances between genomes become available. However, this phylogenetic reconstruction is a very challenging task. For the most simple distance measures (the breakpoint distance and the reversal distance), the problem is NP-hard even if one considers only three genomes. Results: In this paper, we present a new heuristic algorithm that directly constructs a phylogenetic tree w.r.t. the weighted reversal and transposition distance. Experimental results on previously
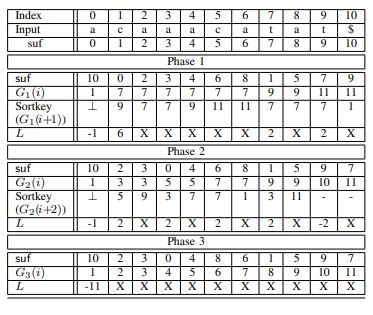
Constructing suffix array during decompression
The suffix array is an indexing data structure used in a wide range of applications in Bioinformatics. Biological DNA sequences are available to download from public servers in the form of compressed files, where the popular lossless compression program gzip [1] is employed. The straightforward method to construct the suffix array for this data involves decompressing the sequence file, storing it on disk, and then calling a suffix array construction program to build the suffix array. This scenario, albeit feasible, requires disk access and throws away valuable information in the compressed
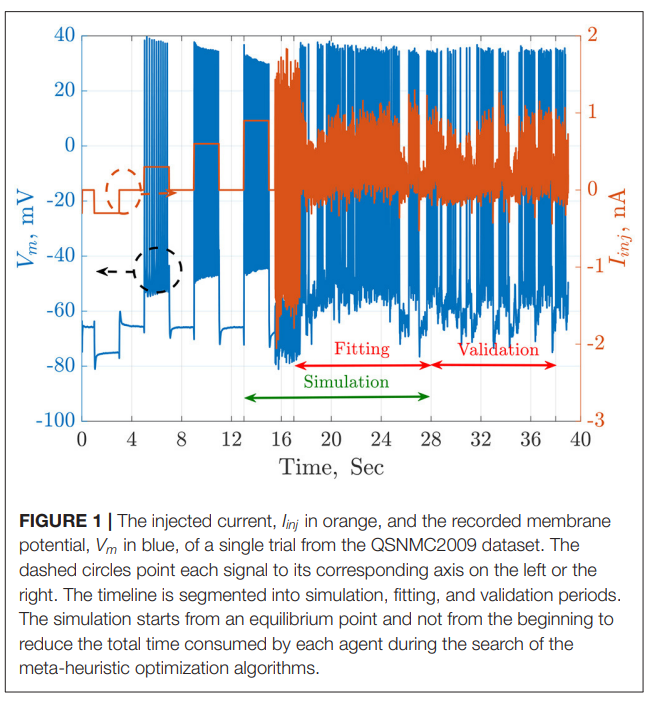
Parameter Estimation of Two Spiking Neuron Models With Meta-Heuristic Optimization Algorithms
The automatic fitting of spiking neuron models to experimental data is a challenging problem. The integrate and fire model and Hodgkin–Huxley (HH) models represent the two complexity extremes of spiking neural models. Between these two extremes lies two and three differential-equation-based models. In this work, we investigate the problem of parameter estimation of two simple neuron models with a sharp reset in order to fit the spike timing of electro-physiological recordings based on two problem formulations. Five optimization algorithms are investigated; three of them have not been used to
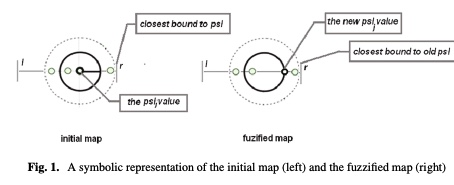
A fuzzy approach of sensitivity for multiple colonies on ant colony optimization
In order to solve combinatorial optimization problem are used mainly hybrid heuristics. Inspired from nature, both genetic and ant colony algorithms could be used in a hybrid model by using their benefits. The paper introduces a new model of Ant Colony Optimization using multiple colonies with different level of sensitivity to the ant’s pheromone. The colonies react different to the changing environment, based on their level of sensitivity and thus the exploration of the solution space is extended. Several discussion follows about the fuzziness degree of sensitivity and its influence on the
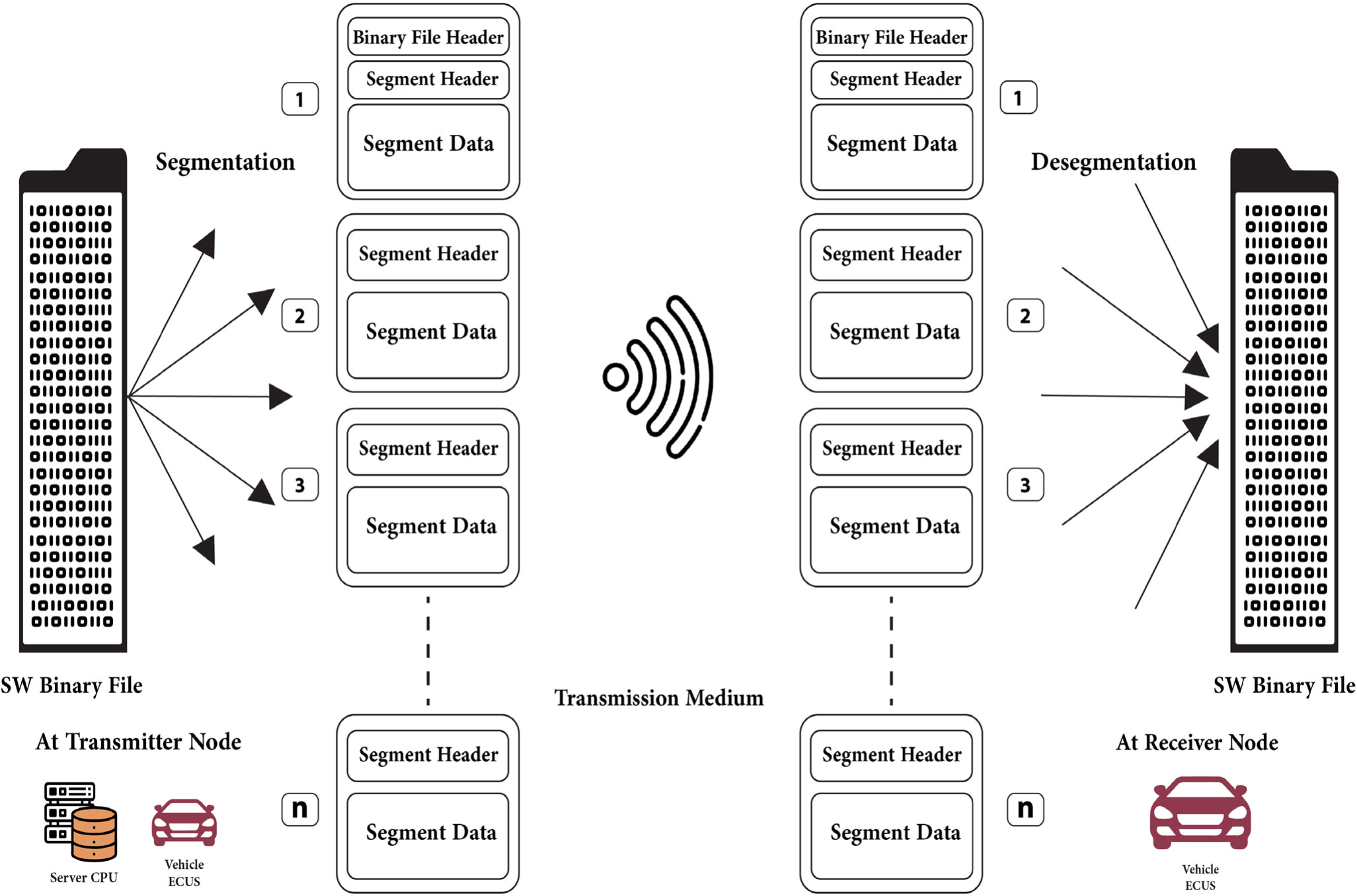
Segmented OTA Platform Over ICN Vehicular Networks
The Internet Protocol (IP) architecture could not fully satisfy the Vehicular Ad-hoc Networks (VANETs) needed efficiency, due to their dynamic topology and high mobility. This paper presents a technique that updates the software of Electronic Control Units (ECUs) in vehicles using segmented Over The Air (OTA) platform over Information-Centric Network (ICN) architecture. In VANET, the amount of time for active vehicles’ connectivity varies due to the vehicular network’s dynamic topologies. The importance of Flashing Over The Air (FOTA) has been illustrated as well as the impact of applying the
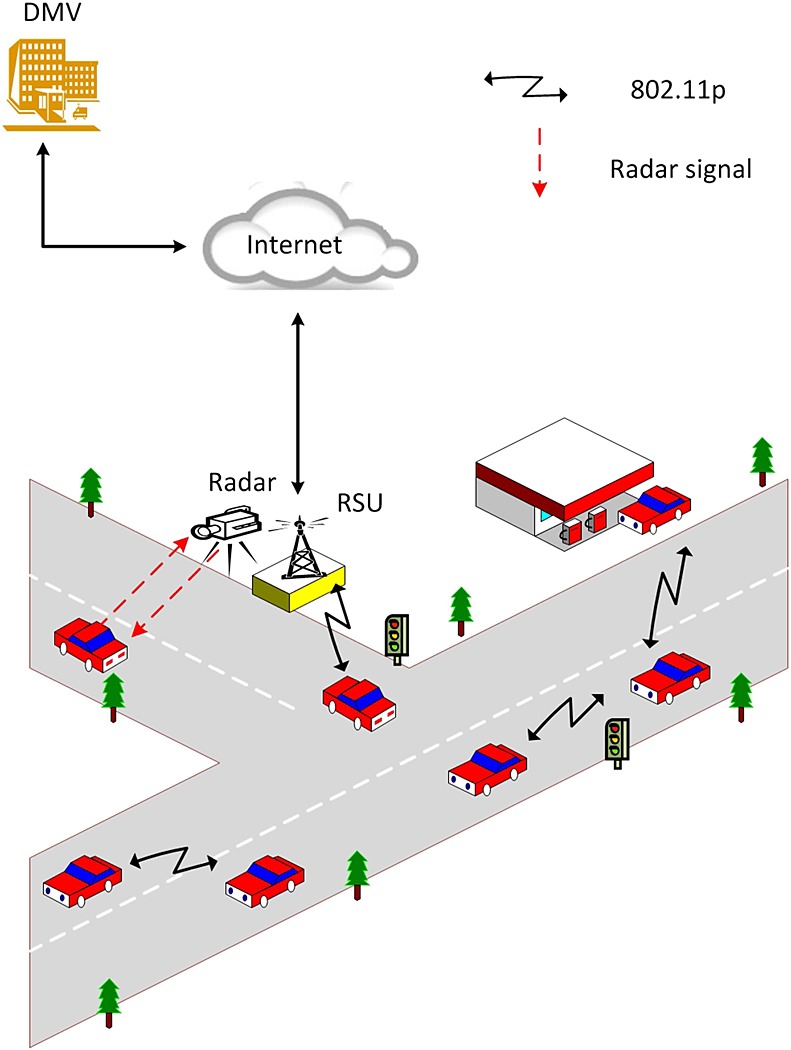
A secure and privacy-preserving event reporting scheme for vehicular Ad Hoc networks
In vehicular ad hoc networks, vehicles should report events to warn the drivers of unexpected hazards on the roads. While these reports can contribute to safer driving, vehicular ad hoc networks suffer from various security threats; a major one is Sybil attacks. In these attacks, an individual attacker can pretend as several vehicles that report a false event. In this paper, we propose a secure event-reporting scheme that is resilient to Sybil attacks and preserves the privacy of drivers. Instead of using asymmetric key cryptography, we use symmetric key cryptography to decrease the
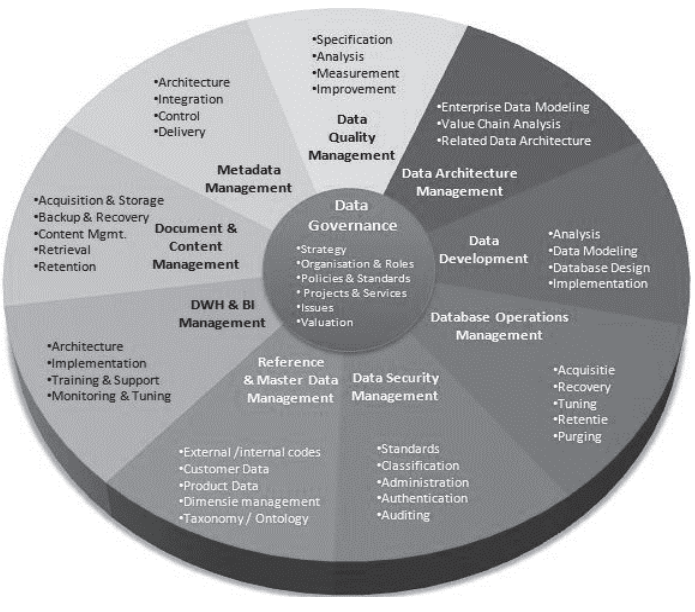
Cloud computing privacy issues, challenges and solutions
There are many cloud computing initiatives that represent a lot of benefit to enterprise customers. However, there are a lot of challenges and concerns regarding the security and the privacy of the customer data that is hosted on the cloud. We explore in this paper the various aspects of cloud computing regarding data life cycle and its security and privacy challenges along with the devised methodology to address those challenges. We mention some of the regulations and law requirements in place to ensure cloud customer data privacy. © 2017 IEEE.
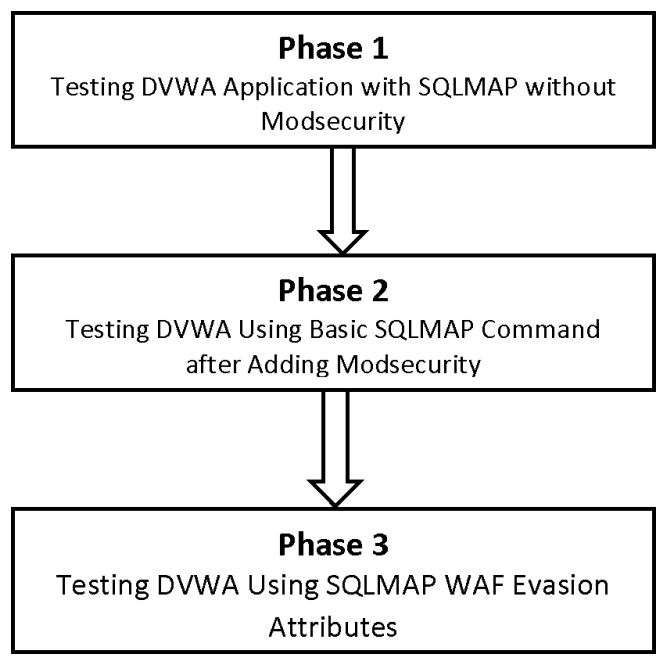
Evaluating the Modsecurity Web Application Firewall against SQL Injection Attacks
SQL injection attacks target databases of web servers. The ability to modify, update, retrieve and delete database contents imposes a high risk on any website in different sectors. In this paper, we investigate the efforts done in the literature to detect and prevent the SQL injection attacks. We also assess the efficiency of the Modsecurity web application firewall in preventing SQL injection attacks. © 2020 IEEE.