
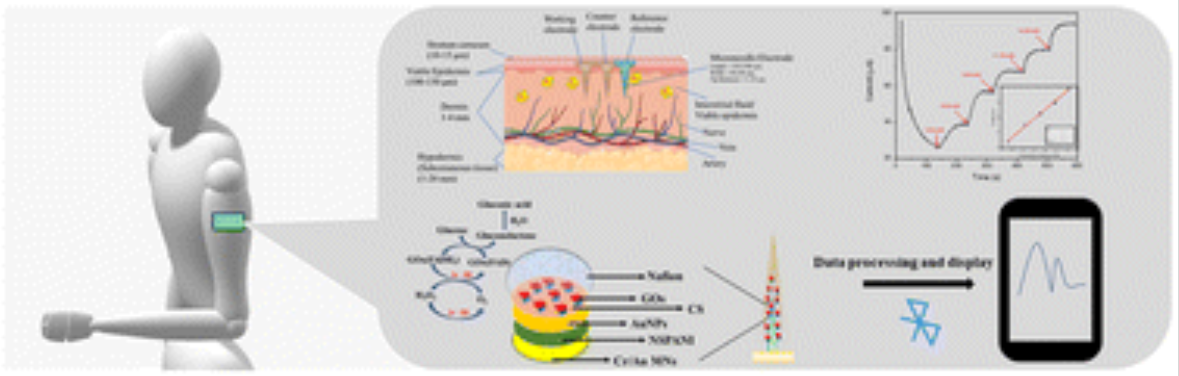
Early detection of hypo/hyperglycemia using a microneedle electrode array-based biosensor for glucose ultrasensitive monitoring in interstitial fluid
Diabetes is a common chronic metabolic disease with a wide range of clinical symptoms and consequences and one of the main causes of death. For the management of diabetes, painless and continuous interstitial fluid (ISF) glucose monitoring is ideal. Here, we demonstrate continuous diabetes monitoring using an integrated microneedle (MN) biosensor with an emergency alert system. MNs are a novel technique in the field of biomedical engineering because of their ability to analyze bioinformation with minimal invasion. In this work we developed a poly(methyl methacrylate) (PMMA) based MN glucose
Synergism between Saccharomyces cerevisiae probiotic and rosemary nano-emulsion: Effect on broiler chicken meat quality and shelf life
Although several studies have investigated the effect of either probiotic feed additives or postmortem meat treatment on the quality of obtained chicken meat, the impact of combined treatment with probiotic feed additives along with meat dipping in essential oil nano-emulsion on meat shelf-life is barely examined. There-fore, this study investigated the effect of combined treatment with Saccharomyces cerevisiae yeast (SCY) and rosemary oil nano-emulsion (RNE) on the quality and shelf-life of chilled broiler meat. The experimental part consisted of adding SCY as a feed additive to broiler
Water Importance and Pollution Sources-Recommended Limits of Pollutants
There are many water resources like rivers, seas, rains, and groundwater, which can be used in different sectors such as agricultural, domestic, and industrial uses. Therefore, different wastewater effluents with different properties are produced depending on their source. Industrial wastewater is one of the most harmful effluents due to the presence of toxic pollutants such as heavy metals, dyes, and other toxic substances. Usually, water is used in different industries for different internal processes, and then the resulting wastewater is discharged without treatment into the water resources
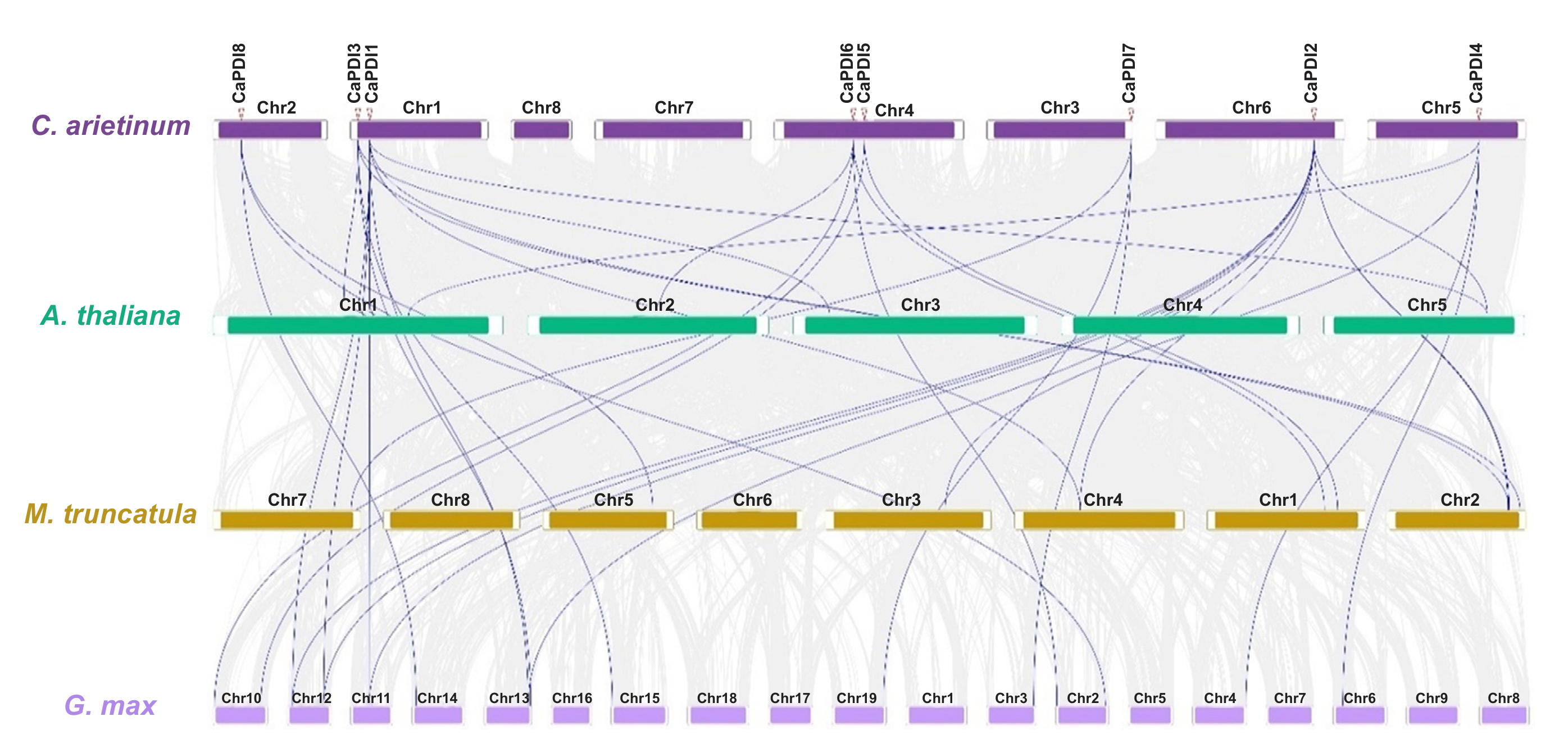
Genome-wide analysis and expression divergence of protein disulfide isomerase (PDI) gene family members in chickpea (Cicer arietinum) under salt stress
Chickpea (Cicer arietinum) is a grain crop that is an important source of protein, vitamins, carbohydrates and minerals. It is highly sensitive to salt stress, and salt damage to cellular homeostasis and protein folding affects production. Plants have several mechanisms to prevent cellular damages under abiotic stresses, such as proteins in the endoplasmic reticulum (protein isulfide somerases (PDIs) and PDI-like proteins), which help prevent the build-up of mis-folded proteins that are damaged under abiotic stresses. In this study, we completed initial comprehensive genome-wide analysis of
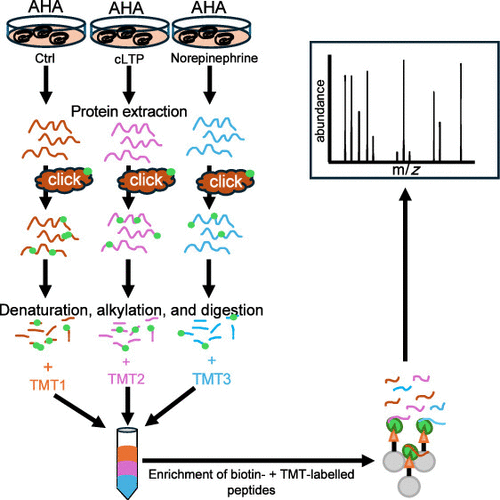
DiDBiT-TMT: A Novel Method to Quantify Changes in the Proteomic Landscape Induced by Neural Plasticity
Direct detection of biotinylated proteins (DiDBiT) is a proteomic method that can enrich and detect newly synthesized proteins (NSPs) labeled with bio-orthogonal amino acids with 20-fold improved detectability compared to conventional methods. However, DiDBiT has currently been used to compare only two conditions per experiment. Here, we present DiDBiT-TMT, a method that can be used to quantify NSPs across many conditions and replicates in the same experiment by combining isobaric tandem mass tagging (TMT) with DiDBiT. We applied DiDBiT-TMT to brain slices to determine changes in the de novo
Review of activated carbon adsorbent material for textile dyes removal: Preparation, and modelling
Water contamination with colours and heavy metals from textile effluents has harmed the ecology and food chain, with mutagenic and carcinogenic effects on human health. As a result, removing these harmful chemicals is critical for the environment and human health. Various standard physicochemical and biological treatment technologies are used; however, there are still some difficulties. Adsorption is described as a highly successful technology for removing contaminants from textile-effluents wastewater compared to other methods. Several adsorbent materials, including nanomaterials, natural

Integrated Analysis of Bulk and Single-Cell Transcriptomics in Cervical Cancer: Insights into BPGM, EGLN3, and SUN1
Cervical cancer (CC) is considered a significant global health threat to women therefore there is a need for personalized treatment strategy based on individual-specific gene expression patterns to enhance recovery and survival rates. Although a few studies have linked bisphosphoglycerate mutase (BPGM) expression with CC, its precise role in CC progression remains unclear. In this study, we conducted an integrated analysis for both bulk and single-cell RNA sequencing data to investigate the involvement of BPGM in CC. On the bulk RNA level, the Wilcoxon test result showed a significant

Applied Techniques for Wastewater Treatment: Physicochemical and Biological Methods
Polluted water is one of the significant challenges facing the world nowadays, especially with the noticed water shortage recorded in the last period. Different treatment methods, physicochemical and biological, were presented for pollutant removal from polluted wastewater. This review discusses the treatment methods starting from the biological part to help reduction of organics, which are solids that appear in the wastewater. After that, the physicochemical techniques will be discussed as a second part of the treatment process to minimize the heavy metal, dyes, and other pollutants
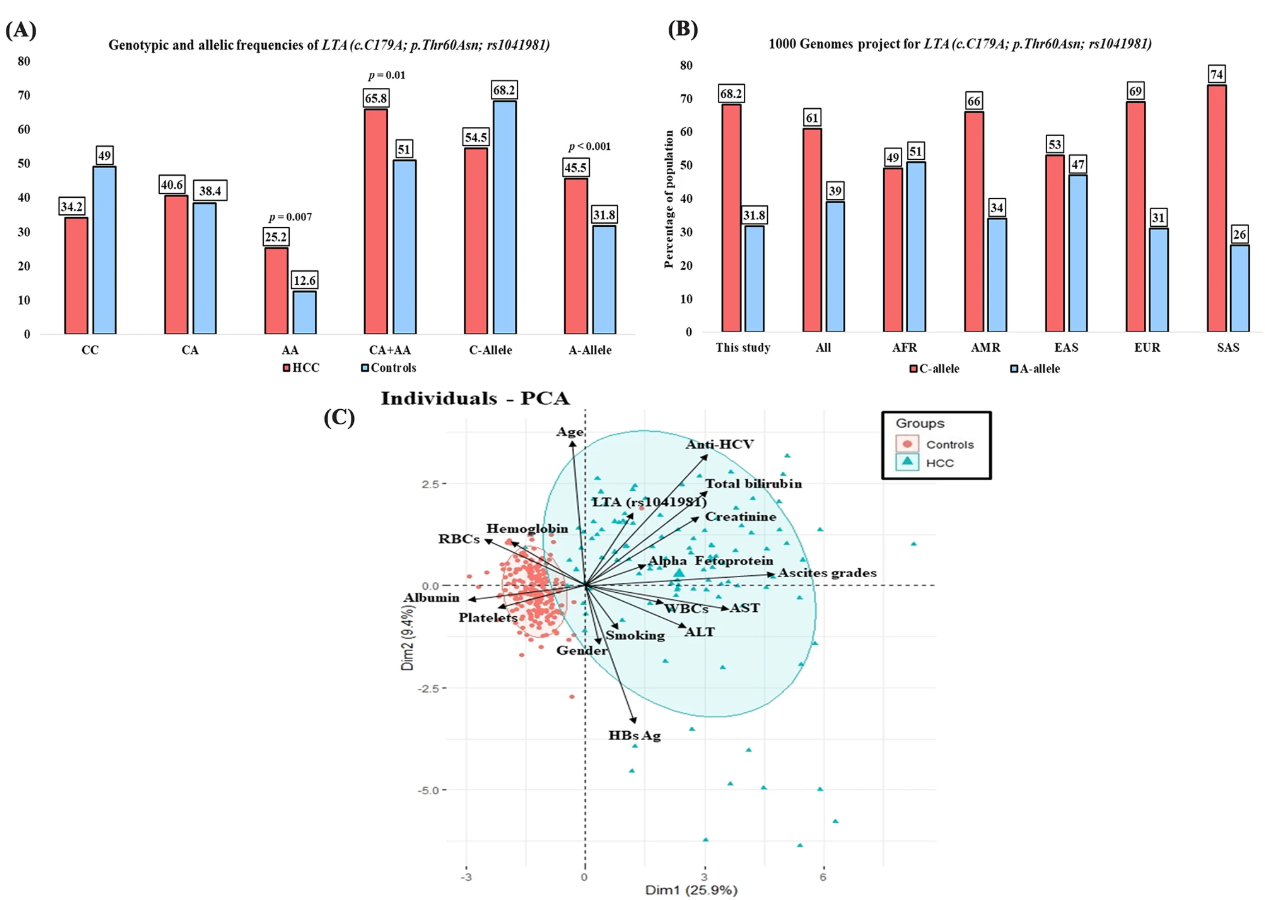
Prognostic significance of the genetic variant of lymphotoxin alpha (p.Thr60Asn) in egyptian patients with advanced hepatocellular carcinoma
Background: Hepatocellular carcinoma (HCC) is one of the most common malignancies worldwide in terms of mortality, and susceptibility is attributed to genetic, lifestyle, and environmental factors. Lymphotoxin alpha (LTA) has a crucial role in communicating the lymphocytes with stromal cells and provoking cytotoxic effects on the cancer cells. There are no reports on the contribution of the LTA (c.179 C>A; p.Thr60Asn; rs1041981) gene polymorphism to HCC susceptibility. The main aim of this study is to investigate the association of LTA (c.179 C>A; p.Thr60Asn; rs1041981) variant with the HCC
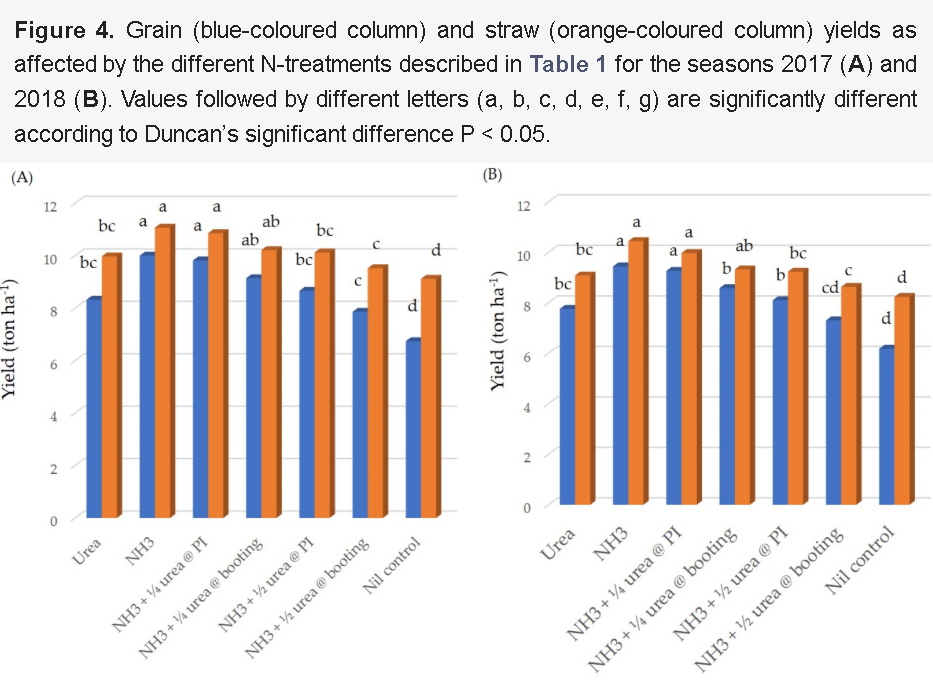
Injected Anhydrous Ammonia Is More Effective Than Broadcast Urea as a Source of Nitrogen for Drill Seeded Rice
Anhydrous ammonia is a cheaper source of nitrogen (N) fertiliser than granular urea for rice production, but it is not widely used in developing countries. It can only be applied pre-crop with any in-crop applications being applied in the form of urea. This 2-year study conducted in the Nile delta region of Egypt compared pre-crop anhydrous ammonia injected to a depth of 20 cm with broadcast urea as N sources for rice, along with 4 combinations of pre-crop ammonia and in-crop urea. Each treatment supplied a total of 165 kg N/ha. The rice crop was direct seeded rather than transplanted. The