
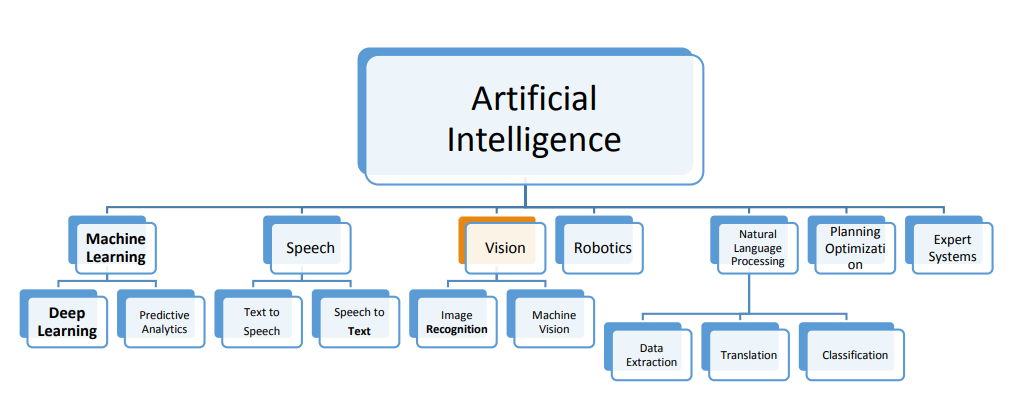
Artificial intelligence for retail industry in Egypt: Challenges and opportunities
In the era of digital transformation, a mass disruption in the global industries have been detected. Big data, the Internet of Things (IoT) and Artificial Intelligence (AI) are just examples of technologies that are holding such digital disruptive power. On the other hand, retailing is a high-intensity competition and disruptive industry driving the global economy and the second largest globally in employment after the agriculture. AI has large potential to contribute to global economic activity and the biggest sector gains would be in retail. AI is the engine that is poised to drive the
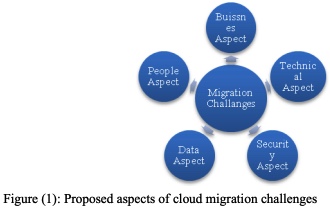
A dynamic system development method for startups migrate to c loud
Cloud computing has become the most convenient environment for startups to run, build and deploy their products. Most startups work on availing platforms as a solution for problems related to education, health, traffic and others. Many of these platforms are mobile applications. With platforms as a service (PaaS), startups can provision their applications and gain access to a suite of IT infrastructure as their business needs. But, startups face many business and technical challenges to adapt rapidly to cloud computing. This paper helps startups to build a migration strategy. It discusses
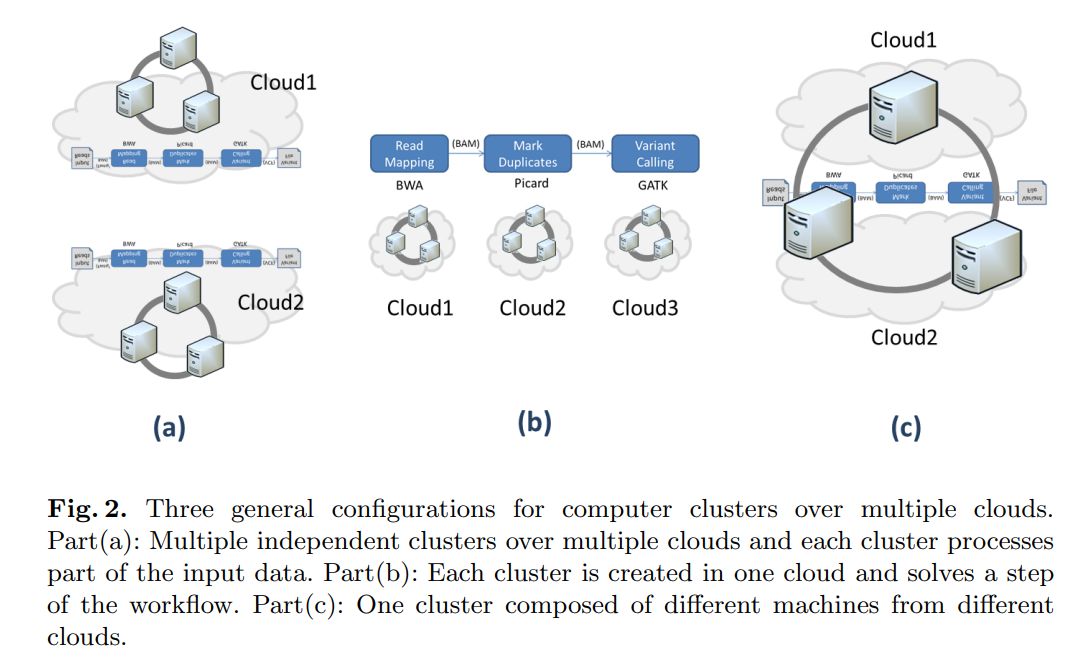
Supporting bioinformatics applications with hybrid multi-cloud services
Cloud computing provides a promising solution to the big data problem associated with next generation sequencing applications. The increasing number of cloud service providers, who compete in terms of performance and price, is a clear indication of a growing market with high demand. However, current cloud computing based applications in bioinformatics do not profit from this progress, because they are still limited to just one cloud service provider. In this paper, we present different use case scenarios using hybrid services and resources from multiple cloud providers for bioinformatics
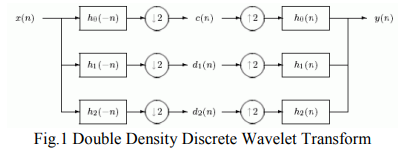
Bivariate Double Density Discrete Wavelet for Enhanced Image Denoising
Image denoising is of paramount importance in image processing. In this paper, we propose a new design technique for the design of Double density Discrete Wavelet Transform (DD DWT) AND DD CWT filter bank structure. These filter banks satisfy the perfect reconstruction as well as alias free properties of the DWT. Next, we utilized this filter bank structure in image denoising. Our denoising scheme is based on utilizing the interscale correlation/interscale dependence between wavelet coefficients of a DD DWT of the noisy image. This is known as the Bivariate Shrinkage scheme. More precisely, we
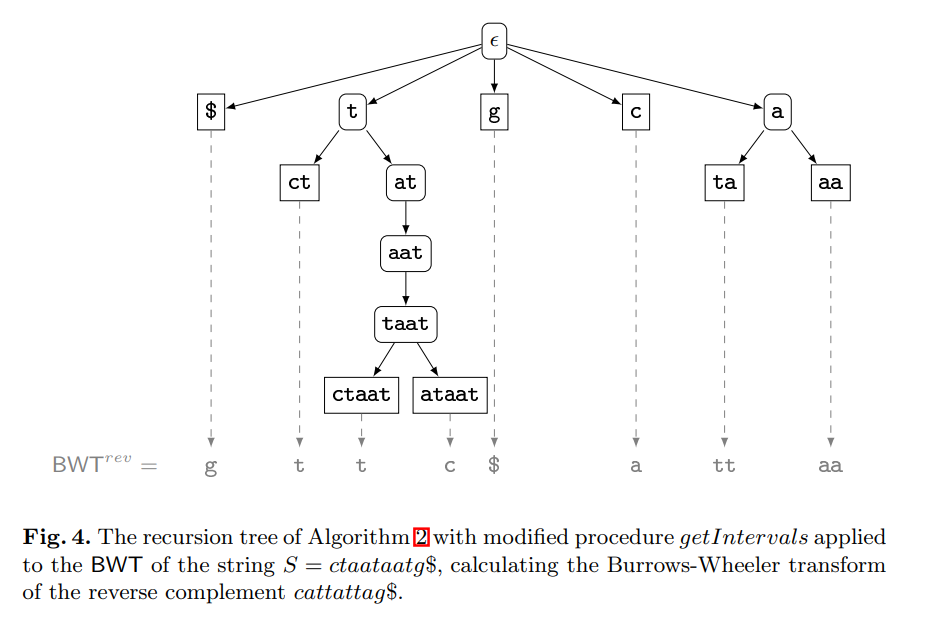
Computing the burrows-wheeler transform of a string and its reverse
The contribution of this paper is twofold. First, we provide new theoretical insights into the relationship between a string and its reverse: If the Burrows-Wheeler transform (BWT) of a string has been computed by sorting its suffixes, then the BWT and the longest common prefix array of the reverse string can be derived from it without suffix sorting. Furthermore, we show that the longest common prefix arrays of a string and its reverse are permutations of each other. Second, we provide a parallel algorithm that, given the BWT of a string, computes the BWT of its reverse much faster than all
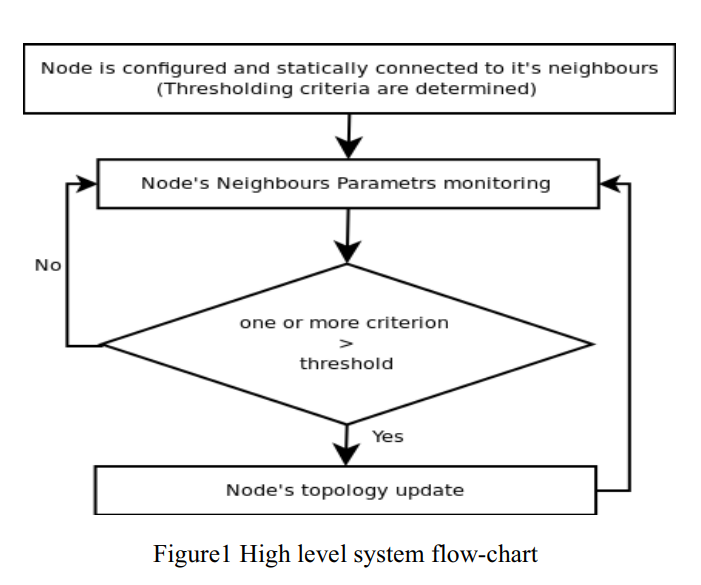
Janitor, certificate and jury (JCJ): Trust scheme for wireless ad-hoc networks
Ad hoc networks are peer mobile nodes that self configure to form a network. In these types of networks there is no routing infrastructure, and usually nodes have limited resources. This imposes a serious problem due to some nodes' selfishness and willingness to preserve their resources. Many approaches have been proposed to deal with this problem and mitigate the selfishness; amongst these approaches are reputation systems. This paper proposes a reputation system scheme that helps isolating misbehaving nodes and decreasing their ability to launch an attack on the network. The idea of this
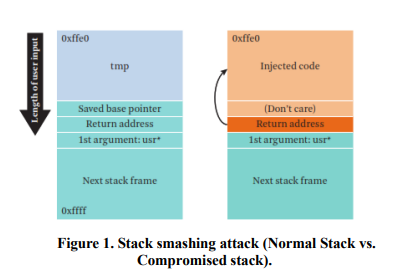
Survey of Code Reuse Attacks and Comparison of Mitigation Techniques
Code-Reuse Attacks (CRAs) are solid mechanisms to bypass advanced software and hardware defenses. Due to vulnerabilities found in software which allows attackers to corrupt the memory space of the vulnerable software to modify maliciously the contents of the memory; hence controlling the software to be able to run arbitrary code. The CRAs defenses either prevents the attacker from reading program code, controlling program memory space directly or indirectly through the usage of pointers. This paper provides a thorough evaluation of the current mitigation techniques against CRAs with regards to
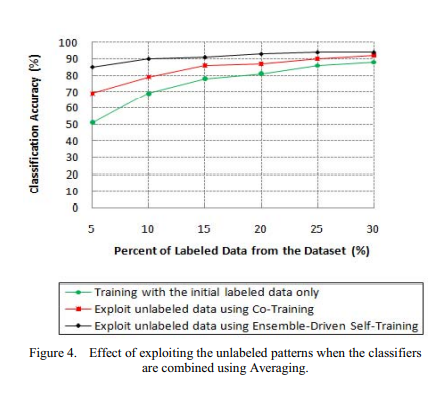
A semi-supervised learning approach for soft labeled data
In some machine learning applications using soft labels is more useful and informative than crisp labels. Soft labels indicate the degree of membership of the training data to the given classes. Often only a small number of labeled data is available while unlabeled data is abundant. Therefore, it is important to make use of unlabeled data. In this paper we propose an approach for Fuzzy-Input Fuzzy-Output classification in which the classifier can learn with soft-labeled data and can also produce degree of belongingness to classes as an output for each pattern. Particularly, we investigate the
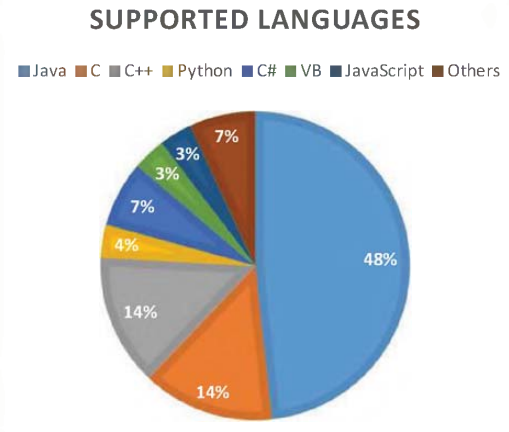
Code Smells and Detection Techniques: A Survey
Design and code smells are characteristics in the software source code that might indicate a deeper design problem. Code smells can lead to costly maintenance and quality problems, to remove these code smells, the software engineers should follow the best practices, which are the set of correct techniques which improve the software quality. Refactoring is an adequate technique to fix code smells, software refactoring modifies the internal code structure without changing its functionality and suggests the best redesign changes to be performed. Developers who apply correct refactoring sequences
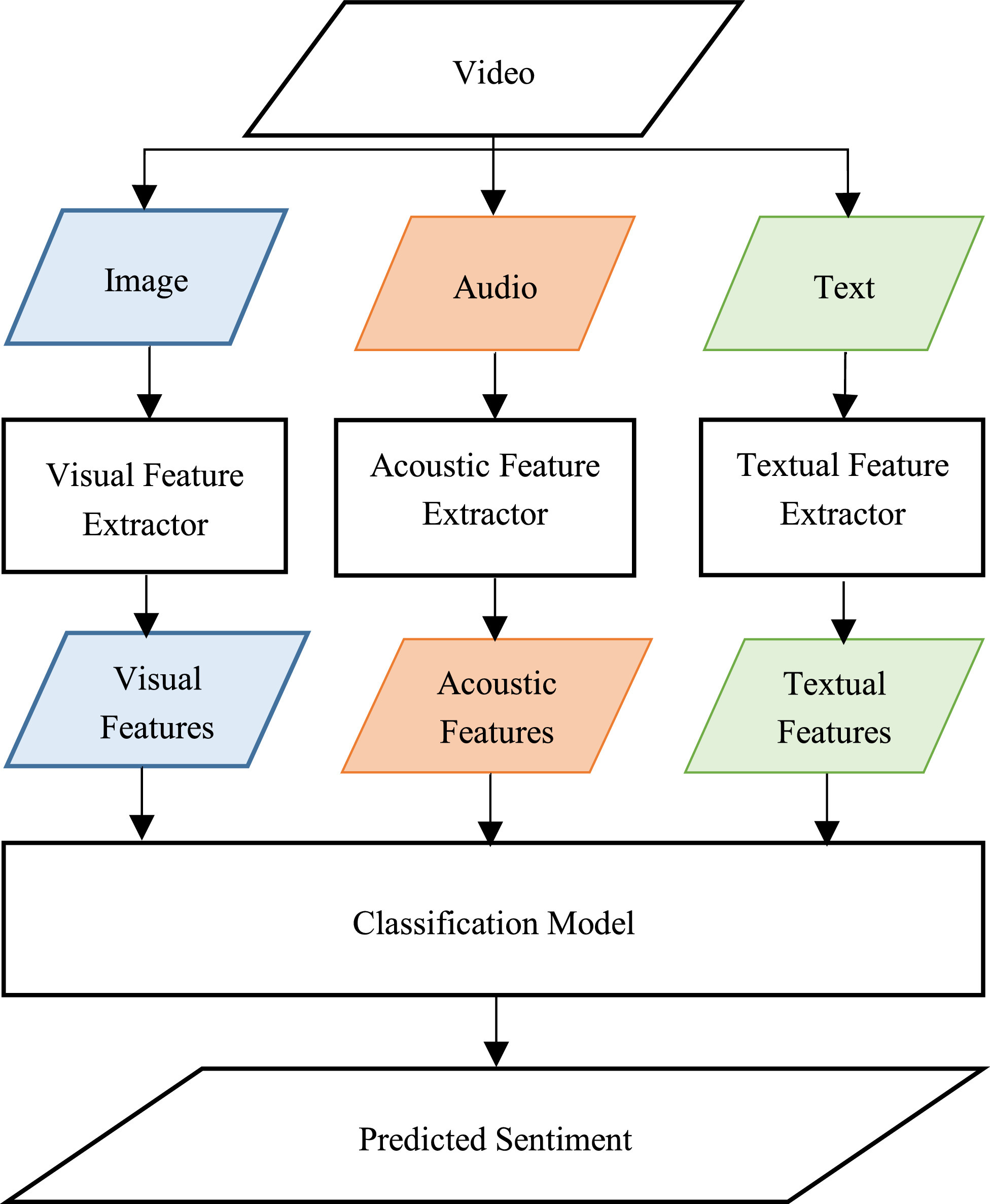
Multimodal Video Sentiment Analysis Using Deep Learning Approaches, a Survey
Deep learning has emerged as a powerful machine learning technique to employ in multimodal sentiment analysis tasks. In the recent years, many deep learning models and various algorithms have been proposed in the field of multimodal sentiment analysis which urges the need to have survey papers that summarize the recent research trends and directions. This survey paper tackles a comprehensive overview of the latest updates in this field. We present a sophisticated categorization of thirty-five state-of-the-art models, which have recently been proposed in video sentiment analysis field, into